Purpose
Why assess a modeling approach?
To understand the value of modeling results, it’s important to determine whether an appropriate model was used given the available data, disease system, and question of interest. Many different types of models exist, and often there is no “gold standard” or standardized framework for model choice or appraisal. As a result, it is important to consider a range of factors when assessing the strength and appropriateness of a modeling approach. Here, we outline key features and considerations when selecting or evaluating a modeling approach.
Is the model structure appropriate for the disease system and questions of interest?
Even if it were possible to perfectly re-create the real world in a model, a more complex model is not always the better choice. Simple models can often illustrate key trends and concepts. However, depending on the question of interest, it may be necessary to add more complex components. Below, we highlight key socio-demographic, biological, and policy questions to consider when assessing whether a model’s structure is appropriate.
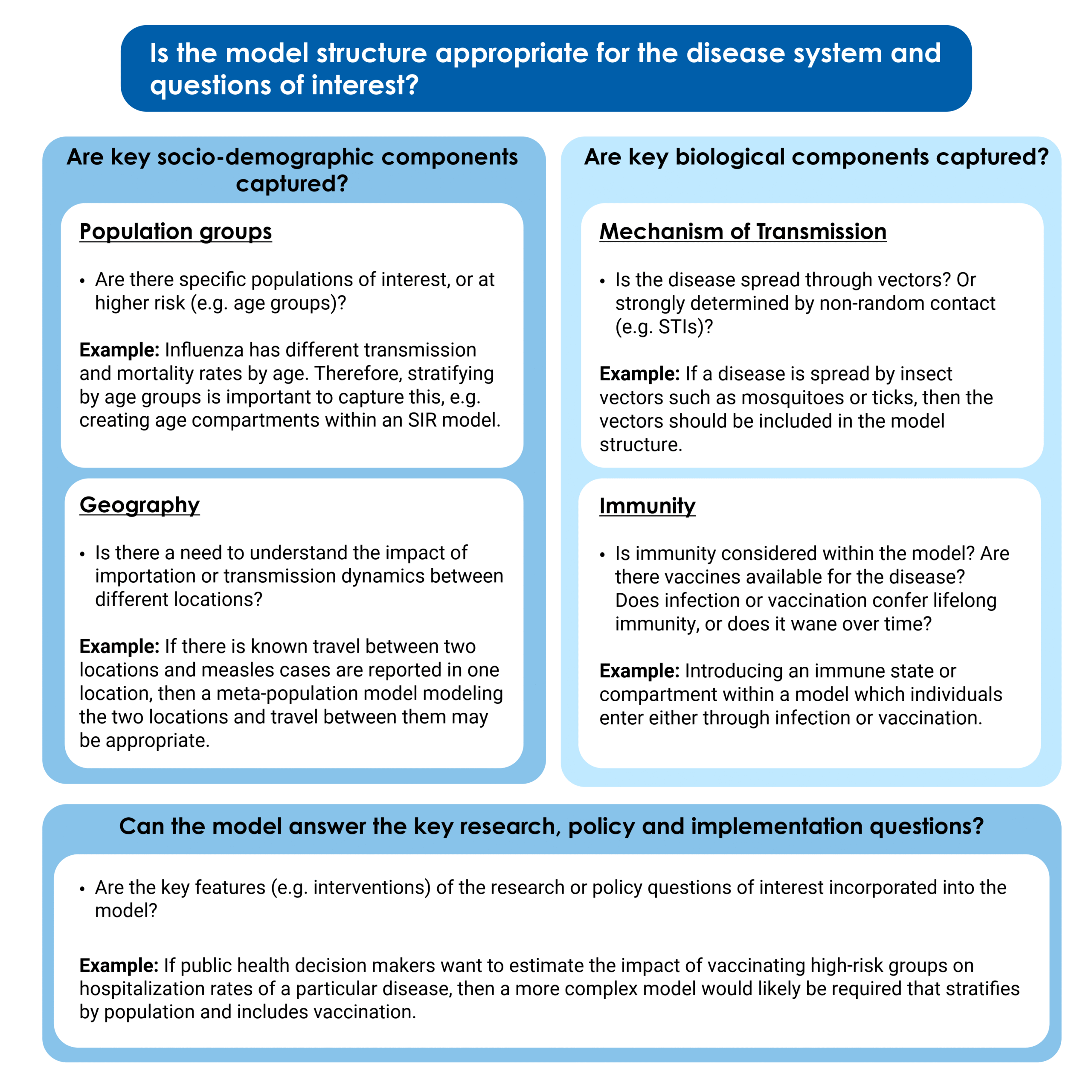
Socio-demographic features such as age, geography, and behavior can be important components shaping transmission dynamics and should be appropriately captured within a model. Different groups within the population may have different transmission routes, rates of infection, or mortality rates from the same disease, which may be important to incorporate into model structure. For example, for respiratory pathogens such as influenza and SARS-CoV-2, social contact patterns, disease severity, and immunity often vary by age. In order to accurately reflect the dynamics of transmission as well as the variable risk posed to different groups, it is important to stratify the model by age and possibly include different model parameters (e.g., contact rates or transmission per contact) by age as well. Social factors such as income and occupation can also affect transmission risk and may need to be modeled explicitly. For example, studies have found that during the COVID-19 pandemic, increased risk of both hospitalization and infection correlated with lower income, higher deprivation, higher poverty, poor housing conditions, and certain types of employment. Geographic location and the degree of travel between different locations can also strongly impact disease dynamics. For example, if we are interested in comparing the impact of vaccination on connected populations with different age structures and population sizes, we will need to choose a model structure that can capture this, such as a metapopulation model, which explicitly models distinct populations and interactions between them, or an individual-based model.
In mechanistic models, the structure of compartments, states, or agents should capture the key components of the biology of the disease system. This includes modeling key components of the mode of disease transmission. For example, if the disease is spread by insect vectors, it may be important for the vectors to be represented in the model (e.g., through creating a vector compartment and/or including a vector biting rate). Similarly, for diseases transmitted through contact with contaminated materials in the environment (including waterborne diseases such as Cholera), the model may include a compartment modeling concentrations of pathogens in bodies of water. If there is an incubation period between exposure to infectiousness and/or symptom onset, it is usually important to include an "exposed compartment" to model that state; otherwise, the timing of disease spread may not be captured appropriately.
Disease immunity has important impacts on transmission of diseases in a population and varies depending on the pathogen and human biology. How it is incorporated into models depends on both the characteristics of immunity and the time scale of the model or modeling question. Some diseases may confer lifetime immunity after infection or vaccination; in others, immunity wanes over time. A model should consider and include immunity, for example, by including an immune compartment or state within the model. Depending on the immunological dynamics of the disease system, the model could incorporate protection from infection, acquired immunity following infection, and the ability to be re-infected if immunity wanes.
In addition to the biology and socio-demographic factors in a disease system, we should consider the research, policy and implementation questions of interest. The research or public health question of interest may be able to be answered with a simple model. In those cases, it wouldn’t be necessary to capture the full complexity of the disease system. However, if the research question specifically includes particular immunological/biological or socio-demographic considerations, it will be important to ensure they are properly included within the system. For example, if the question of interest is in determining the time-varying reproduction number across the entire population, a simple model that is not demographically stratified would likely be sufficient. However, if the question of interest was estimating the impact of vaccinating high-risk groups on hospitalization rates of a particular disease, then a more complex model would likely be required.
Are the inputs and outputs of the model appropriate and accurate?
It is also important to consider both the data and assumptions fed into a model and how the model output is presented.
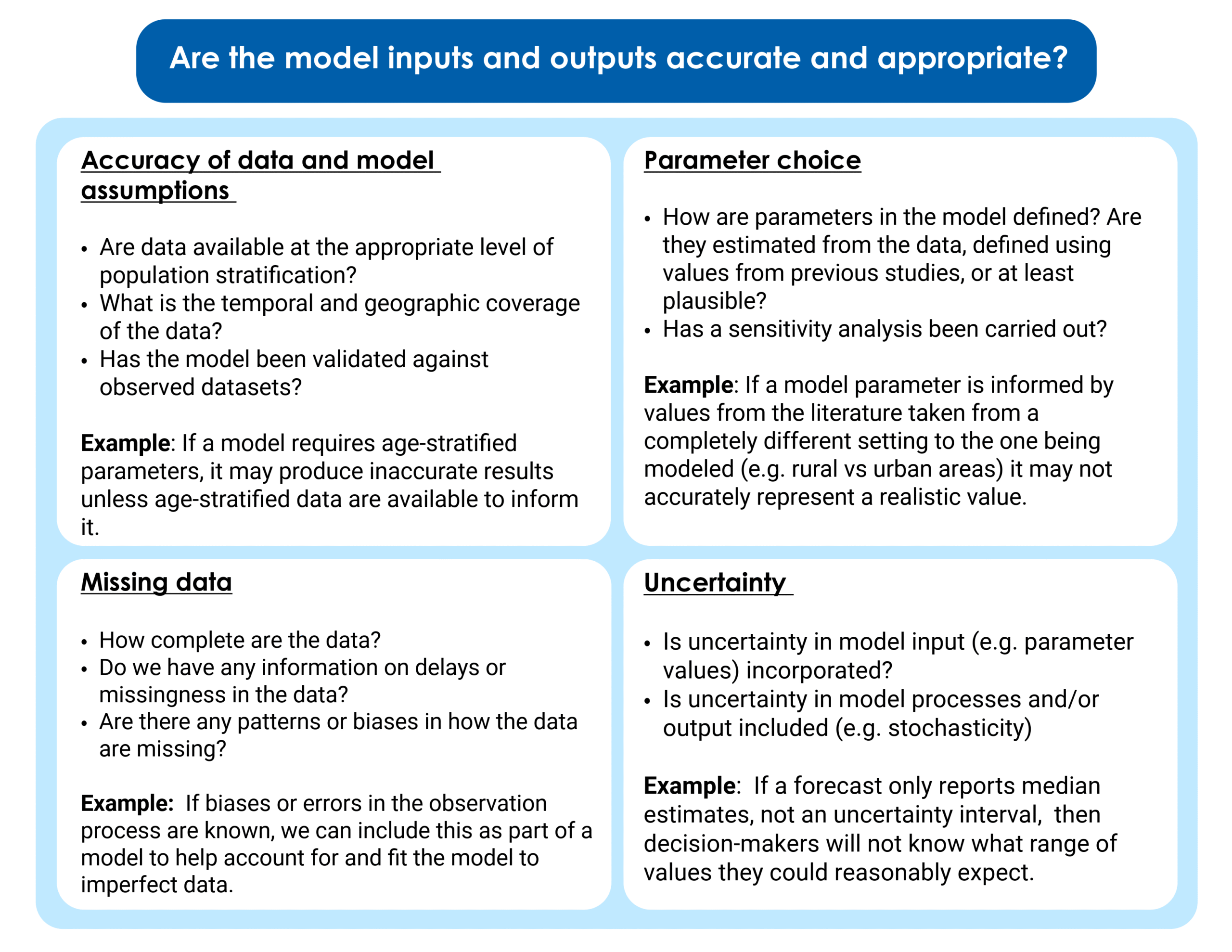
Models are strongly shaped by the data used to produce them. If a model is based upon inaccurate data and assumptions, it will produce results that reflect these inaccuracies. In addition, if we structure a model to include key biological, sociodemographic or implementation components but do not have data to parameterize them, then the model will be limited to “scenarios” or “best-guess” estimates. These estimates may be very far from the true value and produce inaccurate model results. One way of assessing model accuracy is by carrying out model validation and including those results alongside model findings. Model validation is the process of comparing a model to observed datasets to which they have not been fit. This may include fitting a model to data from one period of time and then validating it against another, or applying a model to a new dataset to see if it can replicate the patterns observed. Performing model validation can help us understand whether the model is “overfitted”—meaning the model fits too closely to a particular dataset, including outliers or noise, rather than modeling the key dynamics. This may mean it performs poorly if applied to another dataset or context.
As with any quantitative data analytics approach, it is important to understand if there is "missingness" (missing data) within the underlying data used in model fitting or parameterization. This is particularly important if the missingness has a pattern. There are many ways to account for missing data in a model, but the effects of any assumptions made about why the data is missing should be evaluated as part of the analysis. For example, an observation component can be included, building incomplete observation of data into the model. This is commonly required when incorporating disease surveillance data into a model, as usually not all cases are reported or detected. CFA incorporated models of incomplete observation when modeling Marburg virus, to understand the impact of surveillance efforts on the future trajectory of the outbreak. Another example of an approach to account for missing data is Nowcasting, where delays in reporting are estimated and corrected for to produce real-time estimates of what the likely "final" dataset will look like, once all data have been reported.
The value chosen for each parameter (e.g., how transmissible the pathogen is, how long people are infectious) in a model is key to consider. When choosing parameter values, it is important to ask whether they are consistent with previous literature—or, if there is no previous literature, if they are plausible and informed by evidence from similar pathogens. In addition, it is important to consider whether the parameter value and the data being used to create it actually apply to the context being modeled. For example, differences in access to healthcare between rural and urban areas could lead to different case-fatality ratios for to the same disease. Contact patterns and rates might vary by age and specific population group of interest. If parameter values are being fitted to the data within the model, final estimates should be checked for plausibility and ideally validated against secondary datasets. Sensitivity analyses explore the impact of parameter values on model outputs and the conclusions we make from them. A sensitivity analysis varies key parameters and explores how much changing these parameters changes model results. If the model is more "sensitive" to parameter choice, that means its output changes substantially when parameter values vary. If a model is very sensitive to parameter choice, its results should be interpreted with more caution.
Uncertainty and stochasticity are inherent to infectious disease systems. Quantifying this uncertainty and defining the range of plausible outcomes is essential to support decision-making and preparedness. Uncertainty can be incorporated into a model at several different points. There may be uncertainty in the input parameter values (e.g., population level immunity), or in the processes being modeled, or in the summary statistic reported from the model. Uncertainty in model output (e.g., forecasted hospitalization rates) is often reported using an interval range, which may be a confidence interval, credible interval, or prediction interval. While we are used to seeing confidence intervals given at the 95% interval, credible intervals and prediction intervals are sometimes reported at different levels, with 90%, 80% and 50% being most common. It is important to note which interval is being used when interpreting the uncertainty displayed in model results. When assessing a model, it is useful to look for: whether an appropriate uncertainty interval is reported, whether parameter uncertainty is appropriately included in the model (i.e., through using distributions for parameters rather than single values), and whether random variation is modeled in any way.
Is the model complexity appropriate for the resources and capacity available?

For those implementing models themselves as opposed to just evaluating and using them, resources and capacity also impact model choice. Models can range from extremely simple two-compartment models to highly complex agent-based models that incorporate multiple populations, demographic groups, immunity profiles, interventions and transmission rates. A simplified model is not always less accurate than a more complex model. Simpler models are easier to develop, implement and interpret quickly, and are often necessary for use at the beginning of new outbreaks, or in other scenarios where the speed of an analysis is most important. However, making these simplifications may lead modelers to miss key epidemiological or biological elements of the disease system. More complex models allow more sophisticated scenarios and “real-world” nuances to be taken into consideration, but come at a cost of higher computational resources, lower tractability, and higher technical capacity required of staff implementing and interpreting the model. In turn, they require more time to develop and test and cannot be rapidly built and implemented in response to an emerging outbreak. They also require more data to accurately parameterize.